For cultural heritage and publishing
Automated Indexing
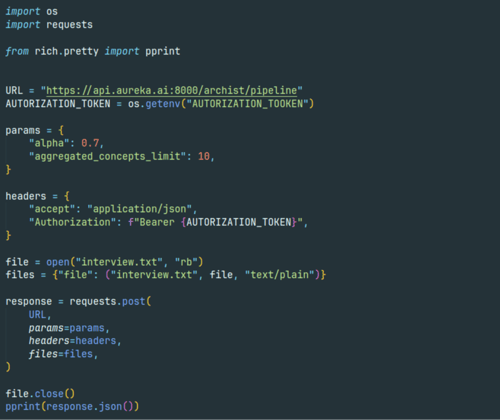
Unlock the power of AI indexing with aureka's Metadata API
- Map concepts to thesauri like the Library of Congress Subject Headings, Gemeinsame Normdatei (GND), BISAC and WGS codes.
- Extract highly relevant keywords for each section and the entire document, prioritized by relevance to enhance search and categorization.
- Summarize the core content of your documents to improve discoverability and enable quick insights.

-1.png?width=600&height=410&name=output%20(1)-1.png)


