
Like most industries, journalism is also affected by the rapid technical developments in the field of Artificial Intelligence (AI). On the one hand, there are many new opportunities to simplify or even completely automate work processes. On the other hand, many questions remain unanswered as to whether and, above all, how AI can be used in investigations and reporting without violating the principles of journalism.
Investigative journalism in particular has repeatedly dealt with investigations into gigantic amounts of data over the past decade. The Panama Papers (2016), the Paradise Papers (2017) and the Pandora Papers (2021) are examples of this type of research, in which thousands of gigabytes of data are analyzed — in these cases to uncover offshore transactions by the super-rich as well as shell companies and international financial flows for tax avoidance.
In order to analyze the enormous amount of data, large media often join forces for this type of research. Hundreds of journalists from many countries work together on the analysis.
Technical aids for investigative journalism
New technical possibilities are already helping to evaluate the enormous amounts of data. These include relatively simple keyword searches as well as Knowledge Graphs. These make it possible to recognize relationships and patterns in the underlying documents that would not be obvious to human researchers due to the sheer volume of data.
Machine Learning and other areas of Artificial Intelligence can uncover connections that remain hidden at first glance. As a result, they can promote investigative stories that might otherwise have remained undiscovered. This ability to recognize patterns is particularly valuable in investigative journalism projects, where the connection between different entities and events often makes the difference between a mundane story and a groundbreaking revelation.
Searching for meaning instead of words
In addition to this structured pattern recognition, methods from Natural Language Processing (NLP) can also help with the exploration of large volumes of text. While keyword searches, for example, can only look at specific combinations of characters (words, word combinations, sentences) — in linguistics this is called “syntactics” — other methods allow us to focus on meanings and concepts. This area of linguistics is called “semantics”, which is why searches based on it are also called “semantic searches”.
What does this mean in concrete terms? Let's assume someone is looking for information on “climate change“. A traditional keyword search would only display results that contain exactly this term. A semantic search, on the other hand, understands that it can also refer to topics such as “global warming“, “greenhouse effect“ or “CO2 emissions“, even if the exact keyword “climate change“ does not appear in the text.
For example, a semantic search could recognize an article about “the effects of increased CO2 levels on ocean temperatures“ as relevant, even if the term “climate change“ is never directly mentioned there. This allows users to get more comprehensive and in-depth information on their search topic, as the search captures and considers the meaning behind the words.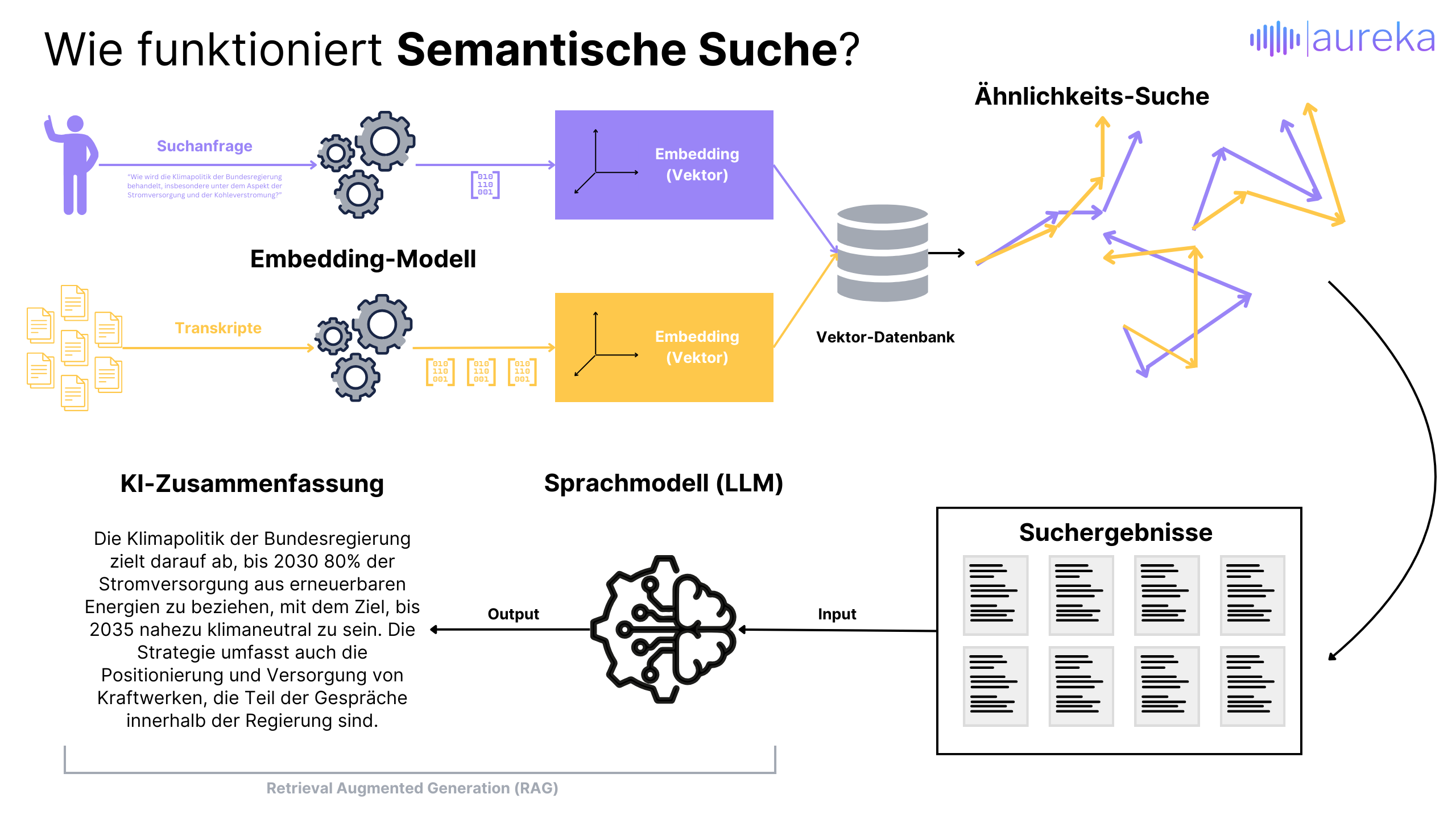
How does a semantic search work?
You can imagine that every word or sentence is converted into a kind of arrow pointing in one direction. In the reality of computers, this happens in a complex space with any number of dimensions that we cannot really imagine. These arrows, called “(vector) embeddings“ or simply vectors, do not represent the position of the words or sentences in space, but their meaning.
When we make a search query, the computer also converts it into such a vector. To find matching results, the computer then searches for vectors that point in a similar direction or are close to each other in space. This process makes it possible to determine the semantic similarity between a search query and the available information.
The key is that it does not search for exact word matches, but for meanings that are reflected in the orientation and position of the arrows in multidimensional space. This allows the semantic search to find content that deals with similar topics or ideas, even if the exact words of our query do not appear there.
Retrieval Augmented Generation (RAG)
And you can take it even further. In a next step, the search results, i.e. the passages from the original material with a high semantic similarity to the search query, can be used as input in a generative language model. Its ability to “understand“ text and provide answers based on this can also be used to make sense of large amounts of data.
The principle behind this is called Retrieval Augmented Generation (RAG). This involves taking the best search results — i.e. the text passages that most closely match the question asked — as a basis and then passing this information to a generative language model (such as GPT-4 or BERT).
The special thing about RAG is that it builds a bridge, so to speak: it first retrieves the relevant information from a huge amount of data and then uses this to create a new answer based on the search query. The language model virtually “reads“ the selected text passages and then formulates an answer that is not only based on general knowledge, but specifically on the information from the search results. This results in answers that go into greater depth and can address the question posed more specifically than if the model only used its previously learned knowledge.
This approach therefore combines the best of both worlds: the ability to filter out relevant information from large amounts of data and the capacity to understand this information and integrate it into a meaningful, coherent response.
Semantic search at aureka
We are doing something very similar at aureka. In future, all transcripts, metadata and annotations uploaded to our platform will be searchable by semantic meaning. Regardless of whether we are talking about ten transcribed interviews or significantly larger amounts of data: With our semantic search, passages in the original material can be found even better and more precisely. This is made possible by the semantic search described above.
This will also help journalists and podcasters to find passages in the transcribed raw material or other materials more precisely and then use them further.
